Cloudant
Cloudant is a distributed NoSQL JSON document store that’s optimized for handling tons of concurrent reads and writes…a workload that is typical of large, global mobile app usage.
You can use Cloudant as a fully-managed DBaaS running on public cloud platforms like SoftLayer, Rackspace, Amazon AWS, and Azure. We’ve also launched an on-premise version of Cloudant Local that you can run yourself on any private or public cloud platform you choose.
It’s RESTful API which makes it easy to access from any language or PaaS. REST defines a set of architectural principles by which you can design Web services that focus on a system's resources, including how resource states are addressed and transferred over HTTP by a wide range of clients written in different languages. To the extent that systems conform to the constraints of REST they can be called RESTful. RESTful systems typically, but not always, communicate over the Hypertext Transfer Protocol (HTTP) with the same HTTP verbs (GET, POST, PUT, DELETE, etc.) which web browsers use to retrieve web pages and to send data to remote servers. REST interfaces usually involve collections of resources with identifiers, for example /people/tom, which can be operated upon using standard verbs, such as DELETE /people/tom.


What makes it really unique is its ability to spread your data out across data centers and devices to scale bigger and deliver data non-stop. Cloudant is ideal for client applications that require massive, elastic scalability to handle millions of daily active users, high availability, geo-location services, full text searches, occasionally connected users and when you require a database schema that needs to be agile and fluid with no waiting or interruption to the application to synch up database schema changes. This makes Cloudant very well suited for mobile applications where the schema evolves quickly.
All this makes Cloudant a great fit for large or fast-growing mobile, web, and IoT apps.
Cloudant is available in 2 forms:
- Fully managed DBaaS running on public cloud platforms.
- Cloudant Local, which you can deploy and manage yourself in your own data centers.
Unless you have your own data centers or have strong data privacy concerns, you’ll probably want to use the Cloudant DBaaS. You can sign up for a Cloudant Multi-tenant account at Cloudant.com and use it for development or prototyping. And for Managed DBaaS production deployment, we recommend Cloudant Dedicated, where we set your Cloudant account up on dedicated, single-tenant clusters in the SoftLayer, Rackspace, Amazon, Azure data center(s) of your choice. Cloudant Dedicated costs a recurring monthly fee based on how many servers in your cluster.
Alternatively, you can run Cloudant Local. It is the same offering as Cloudant DBaaS, but deployed to the private cloud infrastructure of your choice and managed by you, not by Cloudant engineers. Cloudant Local can be licensed on a perpetual or month-to-month basis, and it includes all the DevOps tooling Cloudant uses to run its public cloud DBaaS for easier, safer deployment.
In addition, Cloudant Local and Dedicated are both bare metal, single tenant offerings and Cloudant Local supports seamless "bursting" (replication) of data from on-premises to Cloudant Dedicated on-cloud and Cloudant Local supports geospatial querying & indexing out of the box.
IBM dashDB
In simplest terms, dashDB is IBM’s data warehousing and analytics solution in the cloud. It allows for rapid deployment of large scale data warehouses, provides flexible options for both volume and processing speed, and provides a unified architecture that enables hybrid data processing between on-premise and cloud. It delivers in-database analytics capabilities for the best analytic performance by performing analytics where the data resides rather than moving the data to a separate analytics engine.
dashDB is unique with it’s in-memory acceleration capabilities including columnar technology, advanced compression and buffer pool technology all based on DB2 BLU acceleration. dashDB comes with the in-database predictive analytics and R-support. It’s fully integrated with Cloudant and can serve as a relational data store for Cloudant JSON documents on the cloud. dashDB offers a true “Load and Go” approach without any need for defining indexes in advance. It has built-in Netezza analytics algorithms and also offers built-in Oracle compatibility.
It is a safe and secure environment, with encryption for data at rest, secure connectivity, role-based authentication, and sensitive data reporting.
dashDB can scale-out analytics with its MPP deployment topology.
All this makes Cloudant a great fit for large or fast-growing mobile, web, and IoT apps.


Here are the major use cases for dashDB:
- First, there are of course our existing Netezza and BLU customers evaluating DW as a service offerings in the marketplace. More often than not, this is primarily being done today with AWS Redshift – due more in part to the fact that Redshift was the first DW on the cloud. With dashDB, we have an answer to AWS and other vendors. These customers want to leverage operating cost models (OpEx) and flexible capacity for hybrid application extensions (eg. Market6, CarPhone, Nielsen, EYC, Premier, ..) and dashDB has a compelling and cost-effective approach.
- Second, there are analysts who are building applications leveraging semi-structured data in Cloudant.com (GreenMan, Hothead, etc), and are looking for deeper insight into their customer base by being able to access predictive analytics.
- Third, the are analysts looking to use sophisticated analytics in the cloud which is now possible through dashDB with its Netezza Analytics, R environment, and compatibility with Watson Analytics.
- And finally there are customers simply looking to take their current environments into the cloud, replacing their on premise platforms with cloud-based environments.
DB2 on Cloud
DB2 on Cloud is a hosted cloud service providing a complementary offering to on-premises databases and the opportunity to scale without concern of physical infrastructure. DB2 on Cloud currently blends some of the characteristics of IaaS and PaaS. The customer selects the server configuration based on needs. IBM will then create the VM and install DB2, then address any subsequent VM security patches, management, and restore operations. The customer is responsible for additional DB2 instance creations (a preconfigured, default db2inst1 instance is created for you), HA setup, OS patches, mandatory and optional DB2 patches, fix packs, upgrades, database backup and restore and setting up encryption.
Key features and benefits of IBM DB2 on Cloud are:
- Accelerates and simplifies deployment. Take advantage of DB2 without the need for an on-premises infrastructure.
- Native encryption included with all configurations. You're in control of your data, even when it's not in your building.
- Leverage the benefits of infrastructure as a service with the confidence of knowing your data is encrypted in flight, while in use, and at rest. Optimizes performance and enhances security.
- Experience speed and reliability with a private virtual machine or dedicated bare-metal.
- Four hardware configurations and two database editions to meet your business demands.
- Keep infrastructure costs in line with the changing needs of the business. Provides SQL compatibility support for Oracle Database applications.
Consider DB2 on Cloud for a variety of operational and analytic workloads, from rapid development and testing of new applications to deployment of production applications. Choose DB2 on Cloud when the time to deliver is short and resources and funding are scarce. Decisions regarding platforms -- cloud or on-premises -- can often be made after deployment.
Based on DB2 software, it comes with a preconfigured instance optimized for online transaction processing applications. But while DB2 on Cloud is configured to support the creation and management of databases for online transaction processing applications, it gives you the flexibility to create your own instances for analytic or mixed workloads. Use of this offering reduces the time required for provisioning and deploying DB2 so more resources can be devoted to developing new solutions and innovation.


IBM BigInsights
BigInsights on cloud gives you the speed, flexibility and support needed for an Hadoop offering on the cloud. You can provision a BigInsights cluster in a matter of a few hours instead of the traditional on-prem deployment time of days to weeks. And, it gives you the option to chose a cluster configuration based on your foreseen workloads. This eliminates the guesswork from the equation and lets you focus on the business rather than the infrastructure. BigInsights on cloud also gives you the flexibility of growing the cluster as your requirements change with minimal intervention.
This gives you transparent access to manage your cluster. BigInsights on cloud comes with 24x7 support and fast resolution to your problems with resident experts. Since the solution is based on bare-metal hardware, you have better performance than virtualized environments. Also, you have an encrypted tunnel with network isolation for best security and performance.
You can use the BigInsights offering that suits your analytics workload and the skillsets you have available. You could simply just choose IBM Open Platform (IOP). For analyst needs, all you would need is the IBM BigInsights Analyst module which includes excel like visualization with BigSheets and ANSI SQL with Big SQL access to the data. For a data scientist you needs more deeper analytics on the data, you can avail of the IBM BigInsights Data Scientist module. This includes the components within the Analyst module plus deeper analytics components including BigR, machine learning and text analytics. The BigInsights Enterprise Management module includes the POSIX distributed file system and advanced scheduling for multi-workload and multi-tenant analytic systems.


BigInsights for Apache Hadoop has three 3 deployment options:You pick the amount of memory you need for each node as small, medium or large.
- Small is for basic data extraction, transformation and file processing.
- Medium is for data lake and warehouse environments and use of Big SQL
- Large is for advanced analytic and intensive data processing using Big R and Text Analytics use cases. Optimizes performance and enhances security.
Once you make this selection the sizing tool will take you through how to calculate the overall number of compute nodes needed for your amount of input data

Spark
IBM sees Apache Spark as the analytics operating system of the future. From a more detail perspective, Spark is an open source in-memory application framework for distributed data processing and iterative analysis on massive data volumes. The benefits of the framework is that it is built for ease of use and development, high speed in memory performance and sophisticated analytics that enables applications in Hadoop clusters, or stand alone, to run up to 100 times faster in memory and 10 times faster when running on disk. According to Gartner 30 percent of near real-time data integration and data management use cases will be supported by stacks that include Apache Spark by 2018.
Spark enables data scientists, developers and data engineers to work together to access all data, build analytic models quickly, iterate fast in a unified programming model, and deploy those analytics everywhere.
You may ask why IBM and Spark, and why now. As data and analytics are embedded into the fabric of business and society – from popular apps to the Internet of Things (IoT) – Spark brings essential advances of large scale data processing. First it dramatically improves the performance of data dependent apps. Second, it radically simplifies the process of developing intelligent apps, which are fueled by data. We see Spark as the foundation for innovation in the community, and we see it integrated into our IBM Analytics Platform and solutions – now and in the future.
![]()

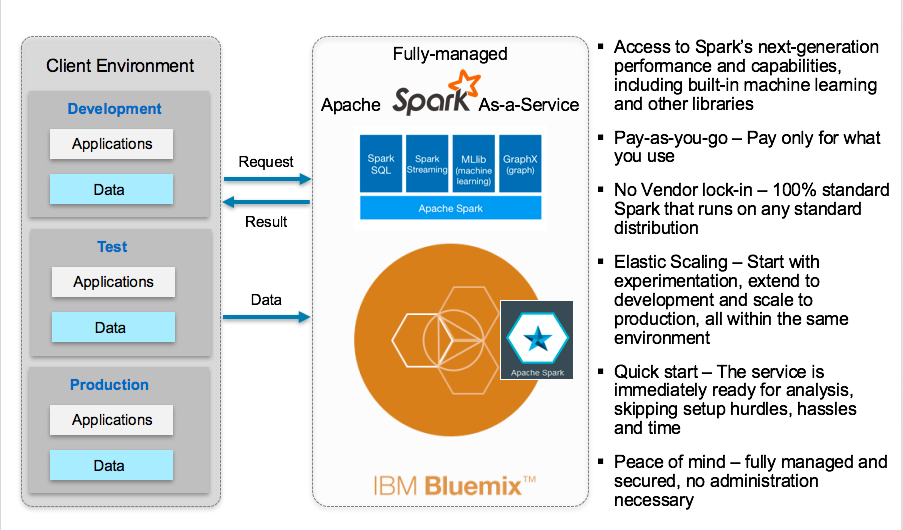
IBM Analytics for Apache Spark (Spark as a Service) is now part of the Cloud Data Services family. It’s a fully-managed cloud based service that provides a Spark environment accessible on-demand and can be accessed from many systems and applications, including Hadoop and the ability to read data from HDFS without requiring Hadoop to run.
The Spark service provides access to Spark’s next-generation performance and capabilities, including built-in machine learning and other libraries. It’s a pay-as-you-go subscription pricing model so you only pay for what you use with no vendor lock-in because its 100% standard Spark that runs on any standard distribution. You can scale as you need and start with experimentation, extend to development and scale to production, all within the same environment. The service is immediately provisioned and ready to do analysis while skipping setup hurdles, hassles and time to value with the peace of mind that it is fully managed and secured by IBM with no administration necessary.
Compose
The IBM Compose Enterprise solution is to provide a single marketplace that encompasses the most active and adopted open source database platforms within the industry today, all easily provisionable within a single platform. For those customers that wish to Self-Host their database platforms, they have the option to do so and leverage the framework that Compose.io has built to easily instantiate and get to work with their database platform.
If the customer would rather have Compose and IBM manage their database(s) for them, they can easily do so with one-click provisioning of their desired environments on AWS or SoftLayer. Compose's elite team of DBAs and system engineers are on-call 24x7 to address any performance or health issues that may arise with their customer's clusters.
The impact to our customers is that they are free to transform and migrate their data from platform to platform within Compose, precisely because of the finely engineered connectors and compatibility that the unified Compose managed platform delivers.
![]()


DataWorks Forge
DataWorks Forge is a fully managed data preparation and movement service for IBM Cloud Data Services that enables business and citizen analysts, developers and data scientists to put data to work.
It provides the ability to access data from on-premises and cloud sources, combining data from different and multiple data sources and then transforming the data using a robust set of transformation actions. It is fully managed by IBM with Pay-as-you-go and subscription pricing options and is powered by Spark for a speedy and responsive experience and is available in Bluemix and seamlessly embedded within Watson Analytics.
Different roles within an organization benefit from the value of DataWorks:- Business and citizen analysts and data scientists can easily find and use the data they need to accelerate data based business decisions using timely, accurate and trusted information.
- Developers can quickly develop data-rich applications by embedding the DataWorks service REST API (Application Programming Interface) into new or existing applications.
- Data engineers can enable self-service access data access to end users using elastic deployment through the cloud and deliver the data faster while maintaining important controls such as data governance and security. This allows them to break free from routine data requests and focus on additional value for an organization such as implementing and enforcing corporate standards, security, data governance and complex requirements.
- DataWorks Forge saves time and resources by reducing the effort to provision trusted data and make it fit for use.


